We’re working in numbers mod 100. Left turns correspond to subtraction, and right turns correspond to addition. To find the position of the dial after a set of turns we just take the cumulative sum of the additions and subtractions (mod 100). Then we just check how many times this position is zero
Code
data = np.array([50] + [int(x.replace("L", "-").replace("R", "")) for x in load(1)])(np.cumsum(data) %100==0).sum()
Part 2
To find the number of times we’ve crossed zero, we can just look at how many times the hundreds place of the running sum has changed - every time that happens, we’ve crossed the value 0 on the dial. This is almost the right answer but needs to be corrected for the fact that sometimes we just kiss zero and don’t cross it. For example, if the dial went 10 -> 0 -> 10, the divisor test wouldn’t show a zero crossing. Similarly, if we went 90 -> 0 -> 90, the divisor test would show two crossings instead of one.
A bit of thinking shows that the relevant points are those where
The total sum is zero after a move
The dial moves in the opposite way in the next move.
We can find both of those cases using numpy magic, and the necessary expression then becomes
There’s probably a clever approach here, but I’m not seeing it right now – I’m guessing that comes with adventing at 9pm after a long day at work. I’ll just iterate over the ranges, and for each range, iterate over the numbers in the range. For every number in the range, I’ll check whether str(number) == str(number)[:length//2] * 2. It’s slow, but it works
Code
ranges = [[int(y) for y in x.split("-")] for x in load(2)[0].split(",")]def invalid_ids(part=1): total =0for val in itertools.chain(*[range(start, end +1) for start, end in ranges]): length =len(str(val)) repeats = [2] if part ==1else proper_factors(length)ifany(str(val)[: length // repeat] * repeat ==str(val) for repeat in repeats): total += valreturn totalinvalid_ids()
Part 2
The advantage of organising part 1 like that is that part 2 can be included in the same function with a small flag to switch between the two code paths. The only thing that’s left to do is to implement a factorisation function and we are done.
Code
@functools.cachedef proper_factors(n): f = [list(set((i, n // i))) for i inrange(2, int(math.sqrt(n)) +1) if n % i ==0]returnsorted([x for pair in f for x in pair] + ([n] if n !=1else []))invalid_ids(part=2)
Once the data is loaded into an array, part 1 can be solved using an ugly one-liner. The idea is to take the largest number in each line, multiply by ten and add the largest number occuring after the first one. This needs to be corrected to account for those cases when the last digit of a line is the largest one - in those cases, we need to take the largest digit occuring before the last slot, multiply by ten and add the last digit.
Code
data = load(3, "intarray")sum( line[firstmax] *10+max(line[firstmax +1 :])if ((firstmax := np.argmax(line)) !=len(line) -1)else line[firstmax] +10*max(line[:-1])for line in data)
Part 2
For part 2, we need to be a bit cleverer, but the core of the logic from before still applies. We know that we need to pick 12 digits out of n. This means that out of the first (n-11) digits, we need to pick at least one – otherwise we’ll run out of digits. And which of those digits is the best one to pick? The largest one. If we pick the ith digit, we now need to pick exactly 11 digits from position i+1 to n, which leads us nicely to the following recursive solution
Code
def optimal_selection(array, count):if count ==0:return []iflen(array) == count:returnlist(array) argmax = np.argmax(array[: len(array) -count +1])return [array[argmax]] + optimal_selection(array[argmax +1 :], count -1)sum(functools.reduce(lambda x, y: 10*x + y, optimal_selection(line, 12)) for line in data)
Once we have that, part 1 could have been expressed as just sum(functools.reduce(lambda x, y: 10*x + y, optimal_selection(line, 2)) for line in data), but I liked the original one-liner
This definitely feels like a job that calls for numpy/scipy’s convolution functions. And maybe that library is such a good fit for the task that using it is a bit like cheating.
For part 1, we can just loop over the values and for every value \(v\) ask if there is some range \(r = (\mathrm{start}, \mathrm{end})\) such that \(\mathrm{start} \leq v \leq \mathrm{end}\). The number of values that we have to check is small enough that this runs plenty fast
Code
ranges, values = load(5, "raw").split("\n\n")ranges = [[int(x) for x in r.split("-")] for r in ranges.split("\n")]values = [int(x) for x in values.split("\n")]sum(any(start <= value <= end for start, end in ranges) for value in values)
Part 2
For part 2, I didn’t even bother checking if the above approach would have been fast enough. since that’s obviously not the intended path. Instead, we should focus on the ranges themselves. The length of a range \(r = (\mathrm{start}, \mathrm{end})\) is just \(\mathrm{end} - \mathrm{start} + 1\). The only tricky thing is what to do when to ranges overlap – how to detect it, and how to correct for it.
If we sort the ranges by start, then one of the folowing is true:
The first two ranges overlap
No range can overlap with the first range
So we can just sort the ranges by first coordinate, loop over them and check the first two ranges in each loop iteration. If they overlap, we put the merged range back into the list of ranges, and if they don’t we are done merging the first range and can just add it to the total length
There’s nothing particularly tricky to do for part one - load the data, sanitise the white space, and then for each set of integers, either add them all together or multiply them, and finally take the sum of the result
Code
from operator import add, muldata = [re.sub(r"\s+", " ", line).split(" ") for line in load(6)]ops = {"*": mul, "+": add}sum( functools.reduce(ops[problem[-1]], [int(x) for x in problem[:-1]])for problem inzip(*data))
Part 2
Part two is more interesting, since we’ll be needing the whitespace that we just got rid of – time to reload the data. Then, we can just use numpy’s transpose function to flip the data, join the individual digits into one string, and separate the groups of digits using itertools.groupby
Code
data = load(6)operators = re.sub(r"\s+", " ", data[-1]).split(" ")operands = ["".join(row) for row in np.array([[char for char in line] for line in data[:-1]]).T]operands = [list(element)for key, element in itertools.groupby(operands, lambda x: not re.match(r"^\s+$", x))if key]total =0for operator, current_operands inzip(operators, operands): total += functools.reduce(ops[operator], [int(x) for x in current_operands])total
Each row of splitters is a linear transformation of the incoming beam: a beam which doesn’t hit a splitter continues unchanged, while a beam that hits a splitter continues as a beam one slot to the left, and a beam one slot to the right. For me, the most natural way of representing this linear transformation is using a matrix, and applying the transformation is then just a matrix multiplication. Going through all the rows is just a matter of repeated matrix multiplication
Code
data =1* (load(7, "chararray") !=".")[::2]def generate_matrix(indices, length=len(data[0])): m = np.eye(length)for idx in indices: m[idx] = scipy.ndimage.convolve(m[idx], [1, 0, 1])return mtotal, v =0, data[0]for row in data[1:]: total +=sum((v * row !=0)) v = v @ generate_matrix(np.where(row)[0])total
Part 2
I wasn’t planning on it, but with part one solved as I did there, part two just becomes
This is a fairly straightforward implementation of the problem statement. We build an array of all the pairwise (squared) distances, use argsort to find which items they correspond to. We successively merge items based on this order, using a forward and a reverse dictionary to keep track of where each item is
Code
arr = np.array(load(8, "int"))sets = {idx: set([idx]) for idx inrange(len(arr))}positions = {idx: idx for idx inrange(len(arr))}squares = np.triu( (np.diagonal(np.subtract.outer(arr, arr), axis1=1, axis2=3) **2).sum(axis=2))order = squares.ravel().argsort()[(1001*1000) //2 :]def merge_index(idx): p1, p2 = [positions[x] for x in np.unravel_index(idx, squares.shape)]if p1 != p2: sets[p1] |= sets[p2]for label in sets[p2]: positions[label] = p1del sets[p2]for idx in order[:1000]: merge_index(idx)functools.reduce(lambda x, y: x * y, sorted([len(x) for x in sets.values()])[-3:])
Part 2
For part 2, we continue merging until there’s only one group left. The last pairwise distance we considered must be between the two items we are interested in
Code
for idx in order[1000:]: merge_index(idx)iflen(sets) ==1:breakp1, p2 = np.unravel_index(idx, squares.shape)arr[p1, 0] * arr[p2, 0]
To determine whether a rectangle defined by two corners lies entirely within the shape, we need to check the following:
That the other two corners lie within the shape
That none of the lines defining the rectangle cross the border of the shape
If any of the the border lines of the rectangle coincide with a border line of the shape, the normal vectors of the line are oriented in the same way
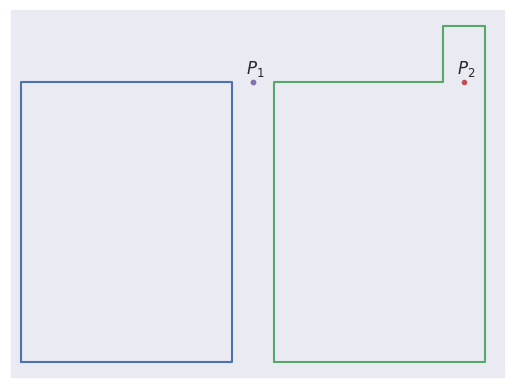
For the first one, we can use a raycasting algorithm and check how many times the ray \((x0 + t, y0),\ t\in[0,\inf)\) intersects with our shape. If the number is odd, the point is inside the shape; if it is even, the point is outside. Points on the edge are counted as being inside the polygon. To account for the edge case where the ray just touches the shape, we’ll say that the tops of the edge line segments count for intersection purposes, while the bottom ones don’t. That lets us distinguish between the following two cases:
Both \(P_1\) and \(P_2\) have two vertical lines from their respective shapes to the left of them, and both lie exactly on the endpoint of either of the lines, yet \(P_1\) is outside the shape while \(P_2\) is inside. The difference between them is that the ray for \(P_1\) touches the tops of two of the edges of the polygon, while the ray for \(P_2\) touches the top of one and the bottom of the other.
With the theory worked out, we can proceed to actually calculating the number we are looking for:
Code
@dataclassclass LineSegment: position: int x0: int x1: int orientation: Literal["h"] | Literal["v"]def __post_init__(self):self.direction =1ifself.x1 <self.x0:self.x0, self.x1 =self.x1, self.x0self.direction =-1def contains_point(self, p, endpoints=False):ifnot endpoints:returnself.x0 < p <self.x1returnself.x0 <= p <=self.x1def intersects(self, other):return (self.orientation != other.orientationandself.contains_point(other.position)and other.contains_point(self.position) )def overlaps(self, other):return (self.orientation == other.orientationandself.position == other.positionandself.x1 > other.x0and other.x1 >self.x0 )def points_to_edges(data): edges = []for start, end inzip(data, data[1:]): dx = end[0] - start[0] dy = end[1] - start[1]if dx ==0: edges.append(LineSegment(start[0], start[1], end[1], "v"))else: edges.append(LineSegment(start[1], start[0], end[0], "h"))return edgesedges = points_to_edges(data)direction = np.sign(sum(e.position * (e.x1 - e.x0) * e.direction for e in edges if e.orientation =="h"))vertical_edges =sorted( [e for e in edges if e.orientation =="v"], key=lambda x: x.position)horizontal_edges =sorted( [e for e in edges if e.orientation =="h"], key=lambda x: x.position)def point_in_polygon(point): x, y = point total =0for edge in horizontal_edges:if edge.position > y:breakif edge.position == y and edge.contains_point(x, endpoints=True):returnTruefor edge in vertical_edges:if edge.position > x:breakif edge.position == x:# print(edge, x, y)if edge.contains_point(y, endpoints=True):returnTrueelif edge.x0 <= y < edge.x1: total +=1returnbool(total %2)for idx in (-np.triu(areas)).ravel().argsort(): i1, i2 = np.unravel_index(idx, areas.shape) p1 = data[i1] p2 = data[i2]ifnot point_in_polygon((p2[0], p1[1])) ornot point_in_polygon((p1[0], p2[1])):continue xmin, xmax =sorted([p1[0], p2[0]]) ymin, ymax =sorted([p1[1], p2[1]])if direction ==1: points = [(xmax, ymax), (xmax, ymin), (xmin, ymin), (xmin, ymax), (xmax, ymax)]else: points = [(xmax, ymax), (xmin, ymax), (xmin, ymin), (xmax, ymin), (xmax, ymax)] rect_edges = points_to_edges(points)for e1, e2 in itertools.product(rect_edges, edges):if e1.intersects(e2) or (e1.overlaps(e2) and e1.direction != e2.direction):breakelse:breakareas[i1, i2]
This could be made significantly faster by using a sweep line algorithm to identify the intersections instead of just trying all of them, but it runs fast enough as is.
Source Code
---title: 2025 Solutions---# Imports```{python}# | eval: true# | output: falseimport dataclassesimport functoolsimport itertoolsimport mathimport operatorimport osimport reimport sysfrom collections import defaultdict, deque, namedtuplefrom dataclasses import dataclassfrom queue import PriorityQueuefrom typing import Literal, Tupleimport matplotlib.pyplot as pltimport more_itertoolsimport numpy as npimport pandas as pdimport scipysys.path.insert(1, "..")import utilsload = utils.year_load(2025)```# [Day 1: Secret Entrance](https://adventofcode.com/2025/day/1)## Part 1We're working in numbers mod 100. Left turns correspond to subtraction, and right turns correspond to addition. To find the position of the dial after a set of turns we just take the cumulative sum of the additions and subtractions (mod 100). Then we just check how many times this position is zero```{python}data = np.array([50] + [int(x.replace("L", "-").replace("R", "")) for x in load(1)])(np.cumsum(data) %100==0).sum()```## Part 2To find the number of times we've crossed zero, we can just look at how many times the hundreds place of the running sum has changed - every time that happens, we've crossed the value 0 on the dial. This is almost the right answer but needs to be corrected for the fact that sometimes we just kiss zero and don't cross it. For example, if the dial went `10 -> 0 -> 10`, the divisor test wouldn't show a zero crossing. Similarly, if we went `90 -> 0 -> 90`, the divisor test would show two crossings instead of one.A bit of thinking shows that the relevant points are those where1. The total sum is zero after a move2. The dial moves in the opposite way in the next move.We can find both of those cases using numpy magic, and the necessary expression then becomes```{python}sum(abs(np.diff(np.cumsum(data) //100))+ ((np.cumsum(data) %100==0)[:-1] * np.diff(np.sign(data)) //2))```# [Day 2: Gift Shop](https://adventofcode.com/2025/day/2)## Part 1 {#part-1-1 id="243d6f36-f834-4365-988d-96eb25722e56"}There's probably a clever approach here, but I'm not seeing it right now – I'm guessing that comes with adventing at 9pm after a long day at work. I'll just iterate over the ranges, and for each range, iterate over the numbers in the range. For every number in the range, I'll check whether `str(number) == str(number)[:length//2] * 2`. It's slow, but it works```{python}ranges = [[int(y) for y in x.split("-")] for x in load(2)[0].split(",")]def invalid_ids(part=1): total =0for val in itertools.chain(*[range(start, end +1) for start, end in ranges]): length =len(str(val)) repeats = [2] if part ==1else proper_factors(length)ifany(str(val)[: length // repeat] * repeat ==str(val) for repeat in repeats): total += valreturn totalinvalid_ids()```## Part 2The advantage of organising part 1 like that is that part 2 can be included in the same function with a small flag to switch between the two code paths. The only thing that's left to do is to implement a factorisation function and we are done.```{python}@functools.cachedef proper_factors(n): f = [list(set((i, n // i))) for i inrange(2, int(math.sqrt(n)) +1) if n % i ==0]returnsorted([x for pair in f for x in pair] + ([n] if n !=1else []))invalid_ids(part=2)```# [Day 3: Lobby](https://adventofcode.com/2025/day/3)## Part 1Once the data is loaded into an array, part 1 can be solved using an ugly one-liner. The idea is to take the largest number in each line, multiply by ten and add the largest number occuring after the first one. This needs to be corrected to account for those cases when the last digit of a line is the largest one - in those cases, we need to take the largest digit occuring before the last slot, multiply by ten and add the last digit.```{python}data = load(3, "intarray")sum( line[firstmax] *10+max(line[firstmax +1 :])if ((firstmax := np.argmax(line)) !=len(line) -1)else line[firstmax] +10*max(line[:-1])for line in data)```## Part 2For part 2, we need to be a bit cleverer, but the core of the logic from before still applies. We know that we need to pick 12 digits out of n. This means that out of the first (n-11) digits, we need to pick at least one – otherwise we'll run out of digits. And which of those digits is the best one to pick? The largest one. If we pick the ith digit, we now need to pick exactly 11 digits from position i+1 to n, which leads us nicely to the following recursive solution```{python}def optimal_selection(array, count):if count ==0:return []iflen(array) == count:returnlist(array) argmax = np.argmax(array[: len(array) -count +1])return [array[argmax]] + optimal_selection(array[argmax +1 :], count -1)sum(functools.reduce(lambda x, y: 10*x + y, optimal_selection(line, 12)) for line in data)```Once we have that, part 1 could have been expressed as just `sum(functools.reduce(lambda x, y: 10*x + y, optimal_selection(line, 2)) for line in data)`, but I liked the original one-liner# [Day 4: Printing Department](https://adventofcode.com/2025/day/4)## Part 1This definitely feels like a job that calls for `numpy/scipy`'s convolution functions. And maybe that library is such a good fit for the task that using it is a bit like cheating.```{python}data = load(4, "chararray")count = scipy.ndimage.convolve(1* (data =="@"), np.ones((3, 3)), mode="constant")changed = (data =="@") & (count <5)changed.sum()```## Part 2For part two, we can take the results from part one and put into a while loop```{python}new_data = data.copy()while changed.sum() >0: count = scipy.ndimage.convolve(1* (new_data =="@"), np.ones((3, 3)), mode="constant") changed =1* ((new_data =="@") & (count <5)) new_data[np.where(changed)] ="."(new_data != data).sum()```\># [Day 5: Cafeteria](https://adventofcode.com/2025/day/5)## Part 1For part 1, we can just loop over the values and for every value $v$ ask if there is some range $r = (\mathrm{start}, \mathrm{end})$ such that $\mathrm{start} \leq v \leq \mathrm{end}$. The number of values that we have to check is small enough that this runs plenty fast```{python}ranges, values = load(5, "raw").split("\n\n")ranges = [[int(x) for x in r.split("-")] for r in ranges.split("\n")]values = [int(x) for x in values.split("\n")]sum(any(start <= value <= end for start, end in ranges) for value in values)```## Part 2For part 2, I didn't even bother checking if the above approach would have been fast enough. since that's obviously not the intended path. Instead, we should focus on the ranges themselves. The length of a range $r = (\mathrm{start}, \mathrm{end})$ is just $\mathrm{end} - \mathrm{start} + 1$. The only tricky thing is what to do when to ranges overlap – how to detect it, and how to correct for it.If we sort the ranges by `start`, then one of the folowing is true:1. The first two ranges overlap2. No range can overlap with the first rangeSo we can just sort the ranges by first coordinate, loop over them and check the first two ranges in each loop iteration. If they overlap, we put the merged range back into the list of ranges, and if they don't we are done merging the first range and can just add it to the total length```{python}ranges =sorted(ranges, key=lambda x: x[0])total =0while (r1 := ranges.pop(0)) and ranges: r2 = ranges[0]if r1[1] +1>= r2[0]: ranges = [[r1[0], max(r2[1], r1[1])]] + ranges[1:]else: total += r1[1] - r1[0] +1total + r1[1] - r1[0] +1```# [Day 6: Trash Compactor](https://adventofcode.com/2025/day/6)## Part 1There's nothing particularly tricky to do for part one - load the data, sanitise the white space, and then for each set of integers, either add them all together or multiply them, and finally take the sum of the result```{python}from operator import add, muldata = [re.sub(r"\s+", " ", line).split(" ") for line in load(6)]ops = {"*": mul, "+": add}sum( functools.reduce(ops[problem[-1]], [int(x) for x in problem[:-1]])for problem inzip(*data))```## Part 2Part two is more interesting, since we'll be needing the whitespace that we just got rid of – time to reload the data. Then, we can just use `numpy`'s transpose function to flip the data, join the individual digits into one string, and separate the groups of digits using `itertools.groupby````{python}data = load(6)operators = re.sub(r"\s+", " ", data[-1]).split(" ")operands = ["".join(row) for row in np.array([[char for char in line] for line in data[:-1]]).T]operands = [list(element)for key, element in itertools.groupby(operands, lambda x: not re.match(r"^\s+$", x))if key]total =0for operator, current_operands inzip(operators, operands): total += functools.reduce(ops[operator], [int(x) for x in current_operands])total```# [Day 7: Laboratories](https://adventofcode.com/2025/day/7)## Part 1Each row of splitters is a linear transformation of the incoming beam: a beam which doesn't hit a splitter continues unchanged, while a beam that hits a splitter continues as a beam one slot to the left, and a beam one slot to the right. For me, the most natural way of representing this linear transformation is using a matrix, and applying the transformation is then just a matrix multiplication. Going through all the rows is just a matter of repeated matrix multiplication```{python}data =1* (load(7, "chararray") !=".")[::2]def generate_matrix(indices, length=len(data[0])): m = np.eye(length)for idx in indices: m[idx] = scipy.ndimage.convolve(m[idx], [1, 0, 1])return mtotal, v =0, data[0]for row in data[1:]: total +=sum((v * row !=0)) v = v @ generate_matrix(np.where(row)[0])total```## Part 2I wasn't planning on it, but with part one solved as I did there, part two just becomes```{python}sum(v)```# [Day 8: Playground](https://adventofcode.com/2025/day/8)## Part 1This is a fairly straightforward implementation of the problem statement. We build an array of all the pairwise (squared) distances, use `argsort` to find which items they correspond to. We successively merge items based on this order, using a forward and a reverse dictionary to keep track of where each item is```{python}arr = np.array(load(8, "int"))sets = {idx: set([idx]) for idx inrange(len(arr))}positions = {idx: idx for idx inrange(len(arr))}squares = np.triu( (np.diagonal(np.subtract.outer(arr, arr), axis1=1, axis2=3) **2).sum(axis=2))order = squares.ravel().argsort()[(1001*1000) //2 :]def merge_index(idx): p1, p2 = [positions[x] for x in np.unravel_index(idx, squares.shape)]if p1 != p2: sets[p1] |= sets[p2]for label in sets[p2]: positions[label] = p1del sets[p2]for idx in order[:1000]: merge_index(idx)functools.reduce(lambda x, y: x * y, sorted([len(x) for x in sets.values()])[-3:])```## Part 2For part 2, we continue merging until there's only one group left. The last pairwise distance we considered must be between the two items we are interested in```{python}for idx in order[1000:]: merge_index(idx)iflen(sets) ==1:breakp1, p2 = np.unravel_index(idx, squares.shape)arr[p1, 0] * arr[p2, 0]```# [Day 9: Movie Theater](https://adventofcode.com/2025/day/9)## Part 1```{python}data = load("9", "int")areas = np.prod(abs(np.diagonal(np.subtract.outer(data, data), axis1=1, axis2=3)) +1, axis=2)areas.max()```## Part 2To determine whether a rectangle defined by two corners lies entirely within the shape, we need to check the following:1. That the other two corners lie within the shape2. That none of the lines defining the rectangle cross the border of the shape3. If any of the the border lines of the rectangle coincide with a border line of the shape, the normal vectors of the line are oriented in the same wayFor the first one, we can use a raycasting algorithm and check how many times the ray $(x0 + t, y0),\ t\in[0,\inf)$ intersects with our shape. If the number is odd, the point is inside the shape; if it is even, the point is outside. Points on the edge are counted as being inside the polygon. To account for the edge case where the ray just touches the shape, we'll say that the tops of the edge line segments count for intersection purposes, while the bottom ones don't. That lets us distinguish between the following two cases:```{python}# | eval: true# | code-fold: true# | code-summary: "Code to generate the plot"# import plotly.express as pximport seaborn as snssns.set_theme()plt.plot([0, 0, 1, 1, 0], [0, 1, 1, 0, 0])ax = plt.gca()ax.set_xticks([])ax.set_yticks([])ax.annotate("$P_1$", [1.07, 1.03])ax.plot([1.1], [1], marker=".")ax.set_xlim(left=-0.05, right=2.3)ax.plot([1.2, 1.2, 2, 2, 2.2, 2.2, 1.2], [0, 1, 1, 1.2, 1.2, 0, 0])ax.annotate("$P_2$", [2.07, 1.03])ax.plot([2.1], [1], marker=".")ax.plot([1.1], [1], marker=".")```Both $P_1$ and $P_2$ have two vertical lines from their respective shapes to the left of them, and both lie exactly on the endpoint of either of the lines, yet $P_1$ is outside the shape while $P_2$ is inside. The difference between them is that the ray for $P_1$ touches the tops of two of the edges of the polygon, while the ray for $P_2$ touches the top of one and the bottom of the other.With the theory worked out, we can proceed to actually calculating the number we are looking for:```{python}@dataclassclass LineSegment: position: int x0: int x1: int orientation: Literal["h"] | Literal["v"]def __post_init__(self):self.direction =1ifself.x1 <self.x0:self.x0, self.x1 =self.x1, self.x0self.direction =-1def contains_point(self, p, endpoints=False):ifnot endpoints:returnself.x0 < p <self.x1returnself.x0 <= p <=self.x1def intersects(self, other):return (self.orientation != other.orientationandself.contains_point(other.position)and other.contains_point(self.position) )def overlaps(self, other):return (self.orientation == other.orientationandself.position == other.positionandself.x1 > other.x0and other.x1 >self.x0 )def points_to_edges(data): edges = []for start, end inzip(data, data[1:]): dx = end[0] - start[0] dy = end[1] - start[1]if dx ==0: edges.append(LineSegment(start[0], start[1], end[1], "v"))else: edges.append(LineSegment(start[1], start[0], end[0], "h"))return edgesedges = points_to_edges(data)direction = np.sign(sum(e.position * (e.x1 - e.x0) * e.direction for e in edges if e.orientation =="h"))vertical_edges =sorted( [e for e in edges if e.orientation =="v"], key=lambda x: x.position)horizontal_edges =sorted( [e for e in edges if e.orientation =="h"], key=lambda x: x.position)def point_in_polygon(point): x, y = point total =0for edge in horizontal_edges:if edge.position > y:breakif edge.position == y and edge.contains_point(x, endpoints=True):returnTruefor edge in vertical_edges:if edge.position > x:breakif edge.position == x:# print(edge, x, y)if edge.contains_point(y, endpoints=True):returnTrueelif edge.x0 <= y < edge.x1: total +=1returnbool(total %2)for idx in (-np.triu(areas)).ravel().argsort(): i1, i2 = np.unravel_index(idx, areas.shape) p1 = data[i1] p2 = data[i2]ifnot point_in_polygon((p2[0], p1[1])) ornot point_in_polygon((p1[0], p2[1])):continue xmin, xmax =sorted([p1[0], p2[0]]) ymin, ymax =sorted([p1[1], p2[1]])if direction ==1: points = [(xmax, ymax), (xmax, ymin), (xmin, ymin), (xmin, ymax), (xmax, ymax)]else: points = [(xmax, ymax), (xmin, ymax), (xmin, ymin), (xmax, ymin), (xmax, ymax)] rect_edges = points_to_edges(points)for e1, e2 in itertools.product(rect_edges, edges):if e1.intersects(e2) or (e1.overlaps(e2) and e1.direction != e2.direction):breakelse:breakareas[i1, i2]```This could be made significantly faster by using a sweep line algorithm to identify the intersections instead of just trying all of them, but it runs fast enough as is.